100% Practical, Personalized, Classroom Training and Assured Job Book Free Demo Now

 +91 9317788822, 9357788822
+91 9317788822, 9357788822
Below, I am going to walk you through some libraries in python which are very helpful for Data Analysis.
Â
Numpy & Pandas are your two evergreen friends on this journey. Both of these libraries are extremely important and the logic developed while studying these two libraries is also helpful in various other languages like SQL.
Â
- Numpy: Numpy is a widely-used Python library. By using NumPy, you can speed up your tasks and interface with other packages present in the Python ecosystem, like scikit-learn, which uses NumPy under the hood. Almost every data analysis or machine learning package for Python leverages NumPy in some way. You may want to have a look at Numpy’s official website to explore some interesting stuff going on with Numpy!
 - Pandas: Pandas might be lazy animals. But Pandas in python is one of the most actively used libraries. It provides extended data structures to hold different types of data. Pandas make Data analysis in python very flexible by providing functions for operations like merging, joining, reshaping, concatenating data, etc. You may want to have a look at Pandas’s official website to explore some interesting stuff going on with Pandas!
Below is an example to walk you through the simple application of these libraries :
Â
import pandas as pd
import numpy as np
x1 = np.array(['a', 'a', 'b', 'b', 'b'])
x2=np.array([50, 250, 100, 400, 350])
x3=np.array([10, 20, 20, 50, 40])
x4=np.array([2, 3, 1, 4, 3])
df1 = pd.DataFrame({'bucket':x1,'quantity':x2, 'risk':x3, 'weight':x4})
df1Output:
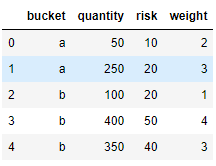
Â
We have a simple table with 4 columns (one nominal and three numerical)
Â
Let’s try to solve below mentioned problems:
- The number of elements as a new col ‘elements’.
- The weighted average of qty and risk, as columns Wtd_AVG_QTY and Wtd_AVG_RISK.Â
Â
df1.groupby('bucket').agg({'bucket': len}).rename(columns={'bucket':Â 'elements'})
Â
df1.groupby('bucket').apply(lambda g: np.average( g.quantity, weights=g.weight)).to_frame('W_AVG_QTY')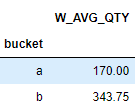
This can also be done by sum(weight*quantity)/ sum(weight).
Â